Sutton & Barto summary chap 01 - Introduction
This is the first post of the Sutton & Barto summary series.
- 1.1. Elements of Reinforcement learning
- 1.2. Limitations and scope
- 1.3. Example
- 1.4. History of reinforcement learning
1.1. Elements of Reinforcement learning
What RL is about:
- trial and error search, delayed reward
- exploration vs exploitation tradeoff
Main elements : agent and environment
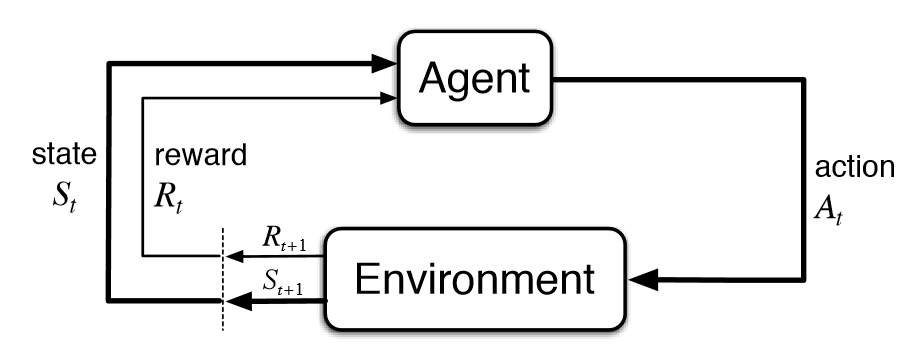 Fig 1.1. Agent and Environment interactions
Fig 1.1. Agent and Environment interactions
Subelements:
- policy $\pi$, mapping from states to actions. May be stochastic
- reward signal: given by the environment at each time step
- value function of a state $V(s)$: total amount of reward an agent can expect to accumulate over the future, starting from that state
- [optional] a model of the environment: allows inferences to be made about how the environment will behave
1.2. Limitations and scope
- state signal design is overlooked
- focus on value function estimation (no evolutionary methods)
1.3. Example
Temporal-difference learning method illustrated with the game of tic-tac-toe:
We want to build a player who will find imperfections in its opponent’s play and learn to maximize its chances of winning.
- We will consider every possible configuration of the board as a state
- For each state keep a value representing our estimate of our probability of winning from this state. We initialize each value in some way (perhaps 1 for all the winning states, 0 for all losing states and 0.5 otherwise)
- Everytime we have to play, we examine the states that would result from our possible moves, and pick the action leading to the state with the highest value, most of the time. That is, we play greedily. Sometimes we may not play the greedy action and pick a random one instead. We would then make an exploratory move.
- While we are playing, we want to make our values more accurate. The current value of the earlier state $V(S_t)$ is updated to be closer to the value of the later state $V(S_{t+1})$:
where $\alpha$ is the step-size paramter controlling the rate of learning. This update rule is an example of temporal-difference learning, which name comes from the fact that its changes are based on the difference $V(S_{t+1}) - V(S_t)$ between estimates at two different times.
1.4. History of reinforcement learning
Major topics in chronological order
- At the beginning there was studies about : trial and error / animal learning / law of effect
- optimal control: designing a controller to minimize a measure of a dynamical system’s behavior over time - value functions and dynamic programming
- temporal difference (TD) methods: driven by the difference between temporally successive estimates of the same quantity
Interesting reference:
- RL + game theory : Reinforcement Learning in Games, Szita 2012